I am Dhaval Adjodah and I am the co-founder and CEO of MakerMaker.AI where we are building AI agents (that build agents)n.
Previously, I was a Program Scientist at Schmidt Sciences funding AI and science research and impact. Earlier, I was a research scientist at the MIT Quest for Intelligence and the MIT Media Lab where I developed new machine learning algorithms using insights from cognitive science and social science. I also did impact-focused work for local communities with the Center of Complex Interventions and consulted for the World Bank to help build machine learning pipelines to track and implement SDG policy.
My PhD thesis was in reinforcement learning and computational social science, during which I was also a member of the Harvard Berkman Assembly on Ethics and Governance in Artificial Intelligence. Previously, I worked as a data scientist in banking and insurance, consulted with the Veterans Health Administration, and founded two startup incubators. I hold a masters degree from the Technology and Policy Program from the (now) MIT Institute for Data, Systems and Society, and a bachelors in Physics, also from MIT.
I enjoy being of service to the computer science and social science communities, most recently as a member of the organizing committee of the AI for Social Good conference workshop series, and on the program committees of the Black in AI initiative and Theoretical Foundations of Reinforcement Learning workshop.
My email is contact dot dval dot me at gmail dot com. Github here. I do not check LinkedIn often.
Highlighted Projects:
Scene Perception for Simulated Intuitive Physics via Bayesian Inverse Graphics
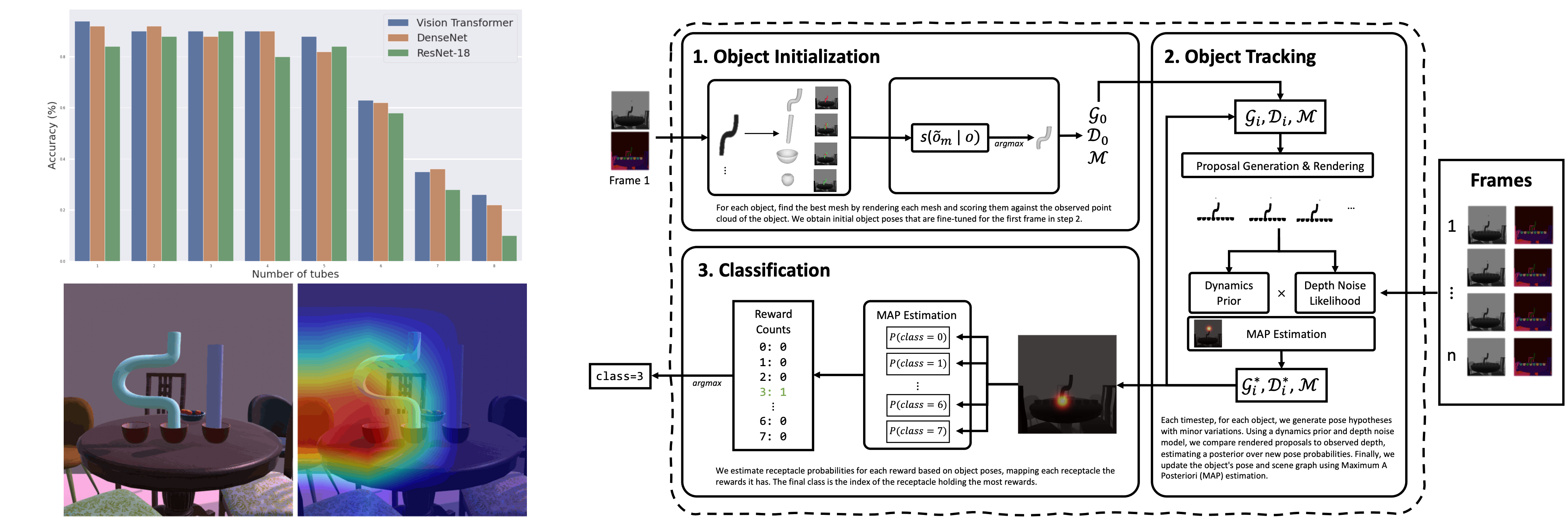
Humans have a wide range of cognitive capacities that make us adept at understanding our surroundings, making inferences even with minimal visual cues. Despite the proficiency demonstrated by deep neural networks, recent works have uncovered challenges in their abilities to encode prior physical knowledge, form visual concepts, and perform compositional reasoning. Inspired by this, we develop the Simulated Cognitive Tasks benchmark, a synthetic dataset and data generation tool, based on cognitive tests targeting intuitive physics understanding in primates. We evaluate recent deep learning models on this benchmark and identify challenges in understanding object permanence, quantities, and compositionality. Therefore, we propose a probabilistic generative model that leverages Bayesian inverse graphics to learn structured scene representations that facilitate learning new objects and tracking objects in dynamic scenes.
[Code]
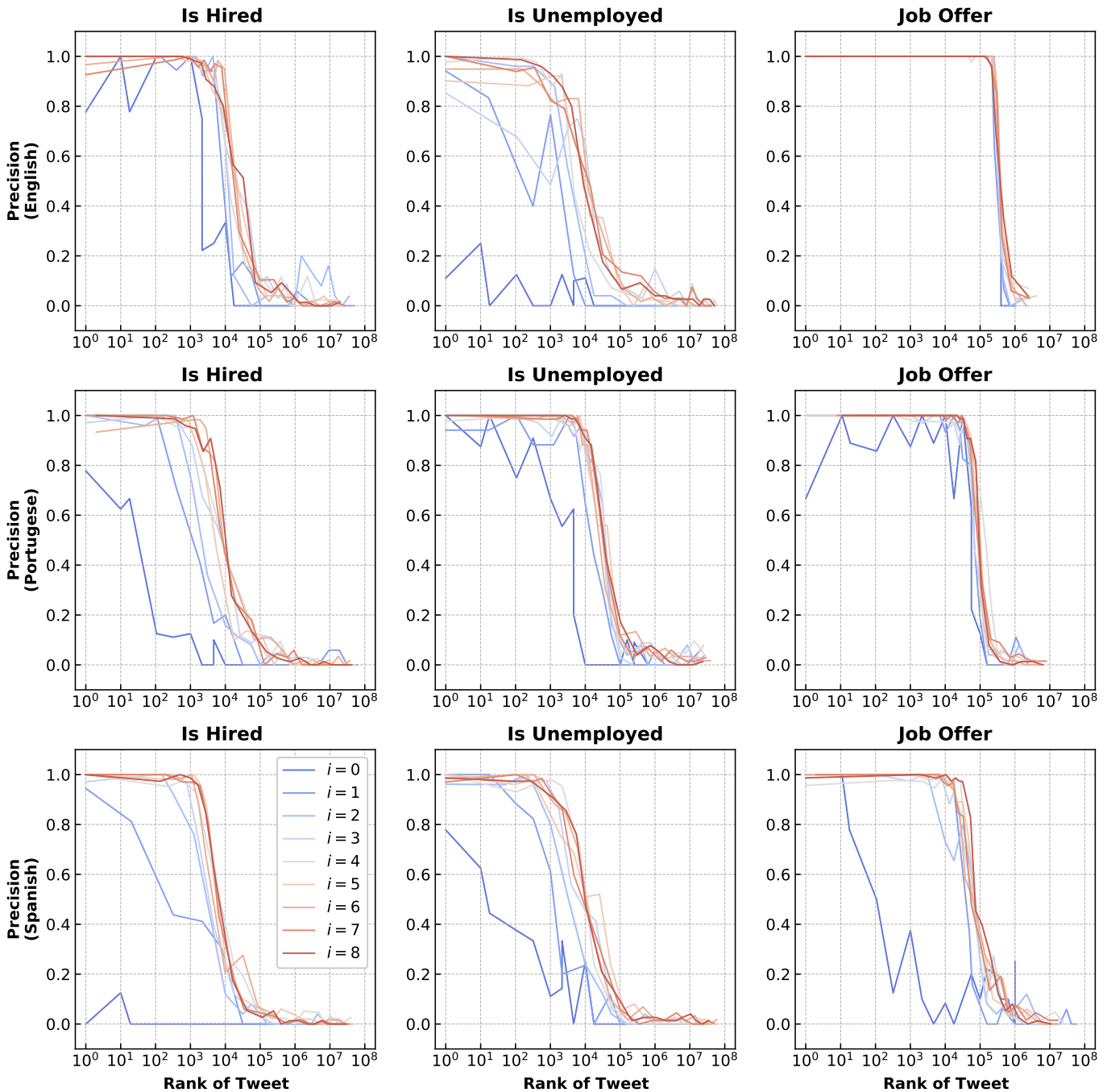
Multilingual Detection of Personal Employment Status on Twitter
We built a Bert-based NLP active learning pipeline to detect extremely rare personal employment disclosures on social media which allows us to
evaluate different active learning strategies for this task across 3 languages. One challenge in this work is the extreme class imbalance setting:
tweets about employment status are extremely rare in the sea of social media content (~1 in 10,000 tweets), which renders random sampling
ineffective for getting a sufficiently large number of positive examples to build a training set. Our Exploit-Explore strategy performs in
line with other more established active learning methods, but with additional bonus of allowing researchers greater interpretability
into the motifs explored by the model at each iteration
[ACL 2022 Paper]
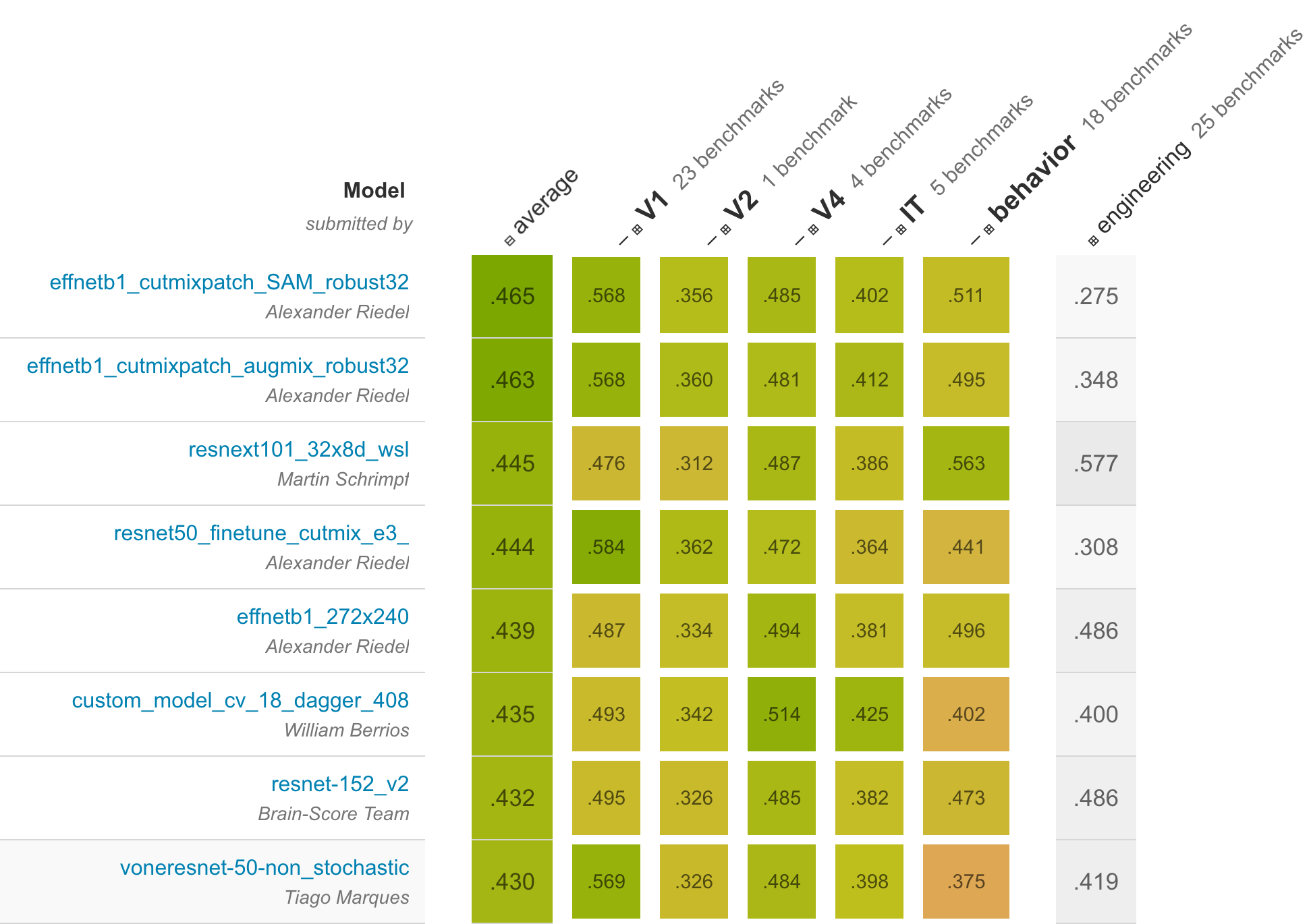
Brain-Score for Computational Language Benchmarking
Our bet is that the closer neural network activations are to the in-vivo human brain recordings (e.g. fMRI), the higher performing will the machine learning models be. We created a software platform with extensible benchmarks to compare neural and human brain as they perform a large variety of langauge tasks. The intent of Brain-Score is to adopt many (ideally all) the experimental benchmarks in the field for the purpose of model testing, falsification, and comparison. To this end, Brain-Score operationalizes experimental data into quantitative benchmarks that any model candidate following the BrainModel interface can be scored on.
[Code]
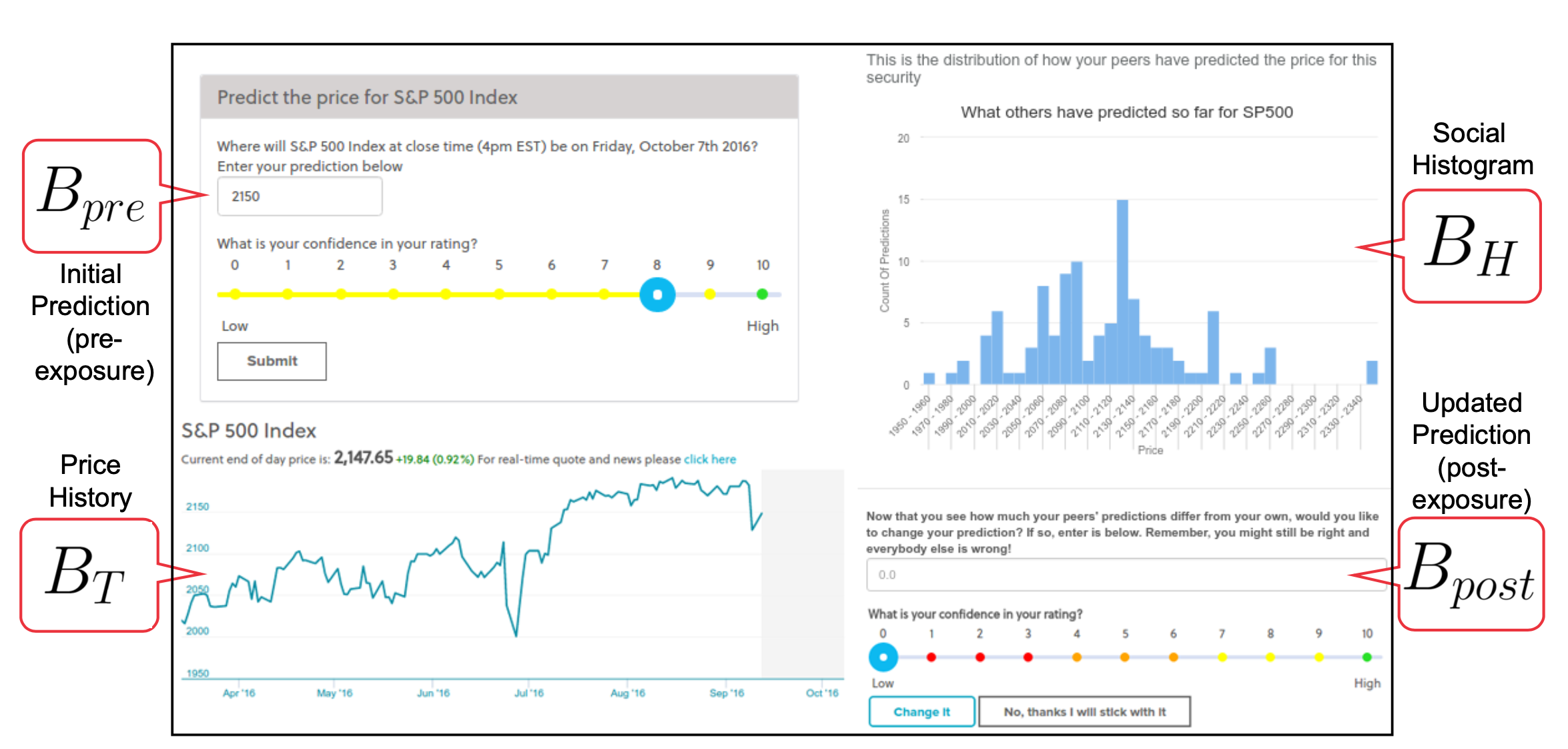
Accuracy-Risk Trade-Off Due to Social Learning in Crowd-Sourced Financial Predictions
A critical question relevant to the increasing importance of crowd-sourced-based finance is how to optimize collective information processing and decision-making. Here, we investigate an often under-studied aspect of the performance of online traders: beyond focusing on just accuracy, what gives rise to the trade-off between risk and accuracy at the collective level? We conducted a large online Wisdom of the Crowd study where 2037 participants predicted the prices of real financial assets (S&P 500, WTI Oil and Gold prices). Using models inspired by Bayesian models of cognition, we show that subsets of predictions chosen based on their belief update strategies lie on a Pareto frontier between accuracy and risk, mediated by social learning.
[Entropy paper link, Code]
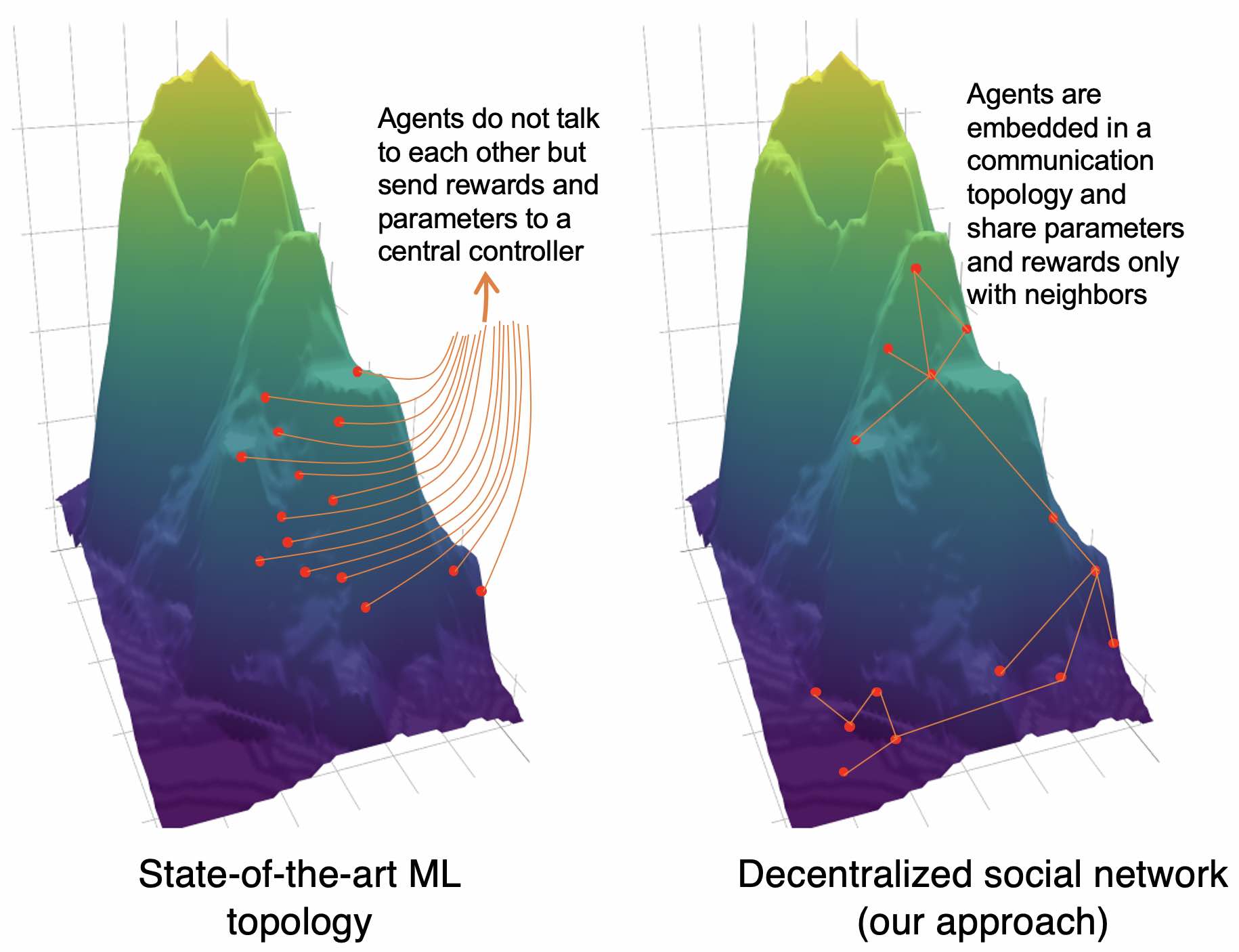
Leveraging Communication Topologies Between Deep RL Agents
There has been a lot of recent work showing that sparsity in neural network structure can lead to huge improvements, such as through the Lottery Ticket Hypothesis. Coming from a computational social science background, we know that humans self-organize into sparse social networks. My hypothesis was that organizing the communication topology (social network) between agents might lead to improvements in learning performance. This is especially important because some machine learning paradigms—especially reinforcement learning—are becoming more and more distributed in order to parallelize learning, similar to how human society balances exploration and exploitation. Well, we find huge improvements: 10–798% improvement on the state-of-the-art robotics simulators! [AAMAS abstract link, Code, Full paper]